Machine Learning
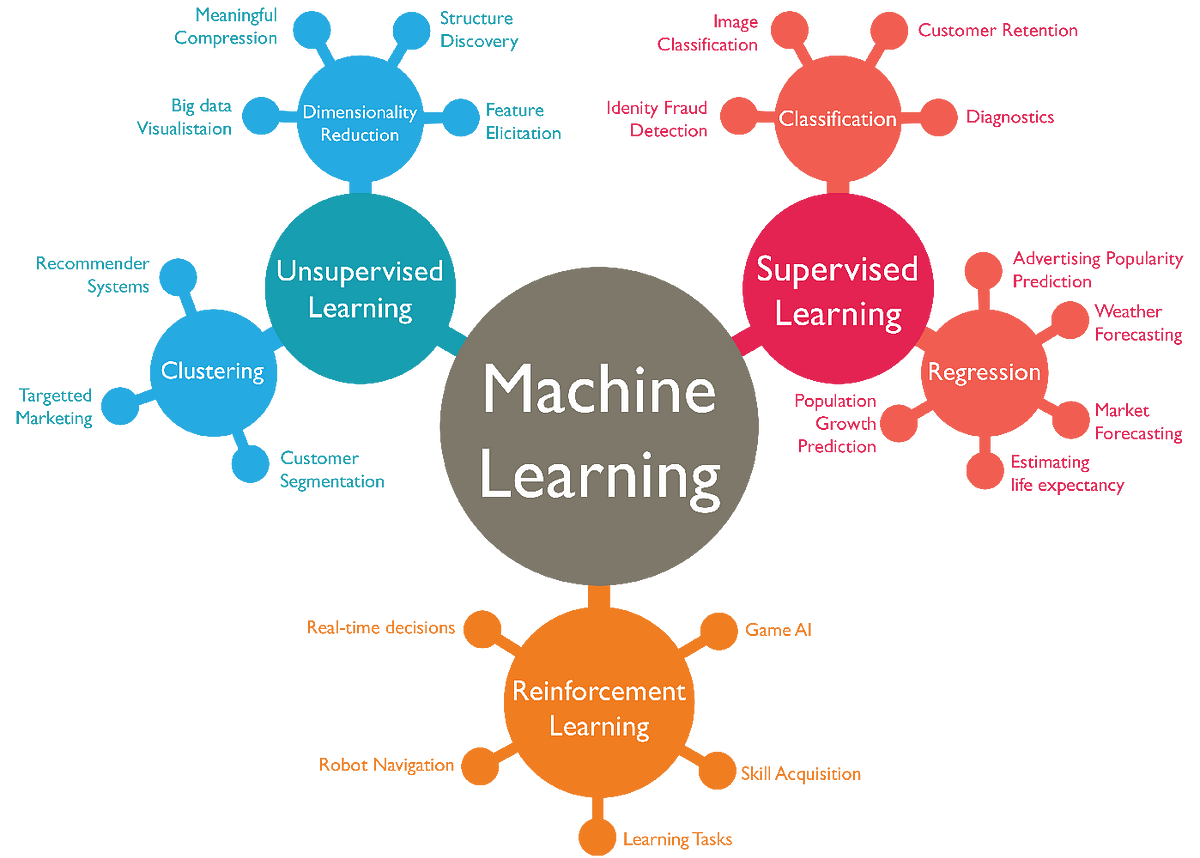
Supervised Learning
监督学习是机器学习和人工智能中的一种算法学习训练方式。它的定义是使用标记数据集来训练算法,以便训练后的算法可以对数据进行分类或准确预测结果。在监督学习中,每个样本数据都被正确地标记过。算法模型在训练过程中,被一系列“监督”误差的程序、回馈、校正模型,以便达到在输入给模型为标记输入数据时,输出则十分接近标记的输出数据,即适当的拟合。
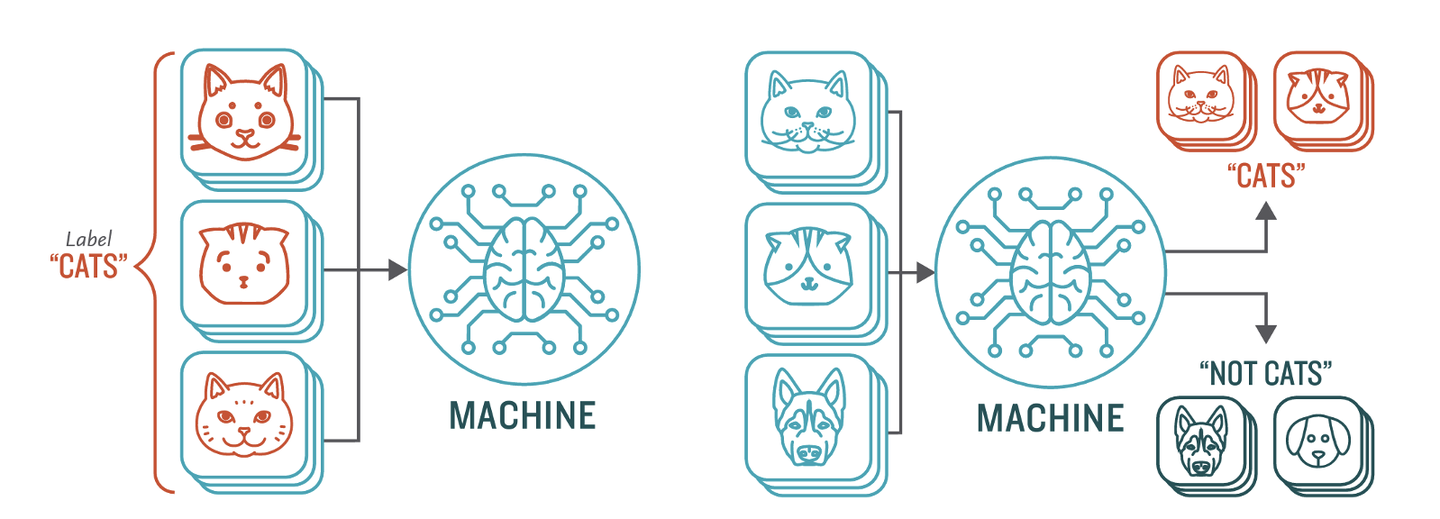
监督学习可以广泛应用于图像识别、自然语言处理、语音识别等领域。监督式学习可分为两类,分类和回归:
分类,Classification,使用一种算法来准确地将测试数据分配到特定的类别中,例如将垃圾邮件从你的收件箱中被识别出来并分类转移到一个单独的文件夹中。线性分类器、支持向量机、决策树和随机森林都是常用的分类算法。
回归,Regression,是另一种监督式学习方法,它使用一种算法来理解因变量和自变量之间的关系。回归模型有助于根据不同的数据点来预测数值,例如某一业务的销售收入预测。
Unsupervised Learning
无监督学习用算法来分析并聚类未标记的数据集,以便发现数据中隐藏的模式和规律,而不需要人工干预。
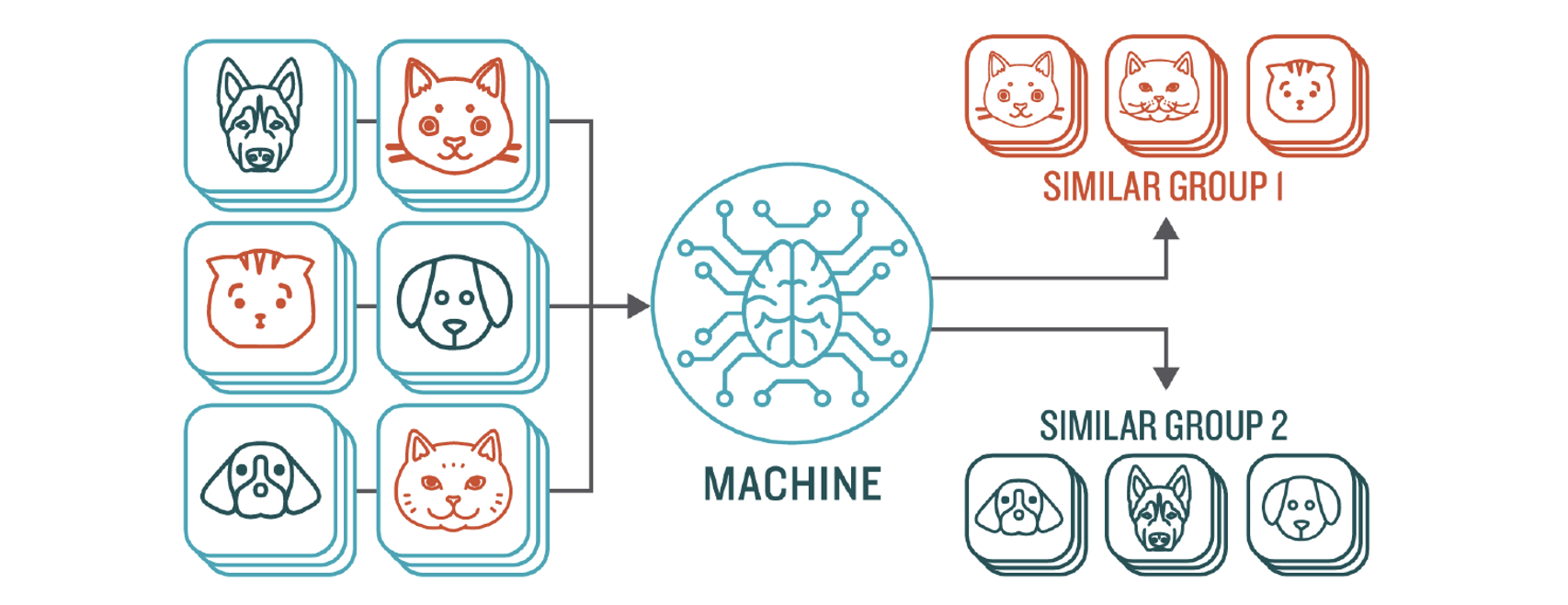
无监督学习模型用于三个主要任务: 聚类、关联和降维:
聚类,Clustering,是一种数据挖掘技术,用于根据未标记数据的相似性或差异性对它们进行分类分组。这个技术适用于细分市场的划分、图像压缩等领域。
关联,Association,使用不同的规则来查找给定数据集中变量之间的关系。 这些方法经常用于“购物车”分析和推荐引擎,类似于“购买此商品的客户也购买了…”这种电商中的推荐算法。
降维,Dimensionality Reduction,当特定数据集中的特征(或维度)太多时,它在保持数据完整性的同时,将数据输入的数量(维度)减少到可管理可操作的大小。要知道有时候数据维度可能达到几千上万或更大的规模,这被称为“维度爆炸”。在这种情况下,我们首先要对数据维度进行筛选去除干扰的无重要意义的维度,即降维。因此,这种技术通常用于数据的预处理阶段,例如用自编码器把图片数据中的噪点去除,以提高图像质量。
其实无监督学习仍然需要人工干预来验证它的输出是否合理。比如数据分析人员需要验证电商推荐引擎将婴儿服装与尿不湿、苹果酱和吸管杯分组是否有实际意义。反过来,如果有一天,算法把两个我们人类看起来毫不相关的两种商品分类到一起,那我们或许会发现某种人类的潜在需求,我们需要认真对待这种分类,但这种潜在需求是否真的存在,我们尚且不知,仍需要市场去检验,但这至少启发了我们。
监督学习与无监督学习的本质区别就在于用来训练的数据是否已经被标注。这也导致了监督学习与无监督学习各有利弊。监督学习在处理大量数据的问题时比较吃力,但是一旦学习到位,其结果将非常准确和值得信赖。而无监督学习可以很轻松地同时处理大量的数据,可是是学习出来的结果不具备透明度,即无法解释。但也因此导致无监督学习可以发掘出许多以前未曾被人类注意的新规律。
Reinforcement Learning
强化学习是一种机器学习技术,它基于反馈的学习方法,对算法执行的正确和不正确行为分别进行奖励和惩罚的制度,目的是使算法获得最大的累积奖励,从而学会在特定环境下做出最佳决策。“强化”一词来自于心理学,心理学中的“强化”就是通过提供一种刺激手段来建立或者鼓励一种行为模式。这种“强化”模式很明显有两种:
积极强化,是指在预期行为呈现后,通过给予激励刺激以增加进一步导致积极反应。
负面强化,通过提供适当的刺激来减少出现负面(不希望的)反应的可能性,从而纠正不希望出现的行为。
想象一下,当你第一次玩马里奥,却没有人指导你怎么玩,你只能自己在游戏中探索环境和重要的 NPC,并随时做好心理准备面对行动的后果。一个错误的举动会导致失去一条“命”,一个正确的跳跃可以把我们带到一个更安全的地方并奖励金币!因此,伴随着奖励和惩罚的探索,牵动着你的大量尝试和错误,最终不断地优化你的行动,让你成为一个马里奥游戏的高手。这就是“强化”训练!
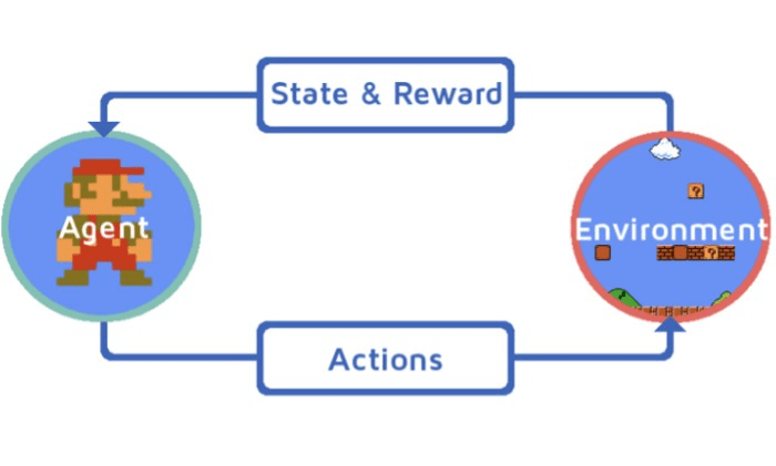
这里有几个“强化”学习的要素需要明确:
代理人(Agent):一个我们试图学习的实体(即玩家在游戏中所使用的角色)
环境(Environment):代理人所处的环境(游戏所设置的游戏世界设定)
状态(State):代理人在环境中获得自己当前状态的各种信息
行动(Actions):代理人在环境中所执行的与环境交互的各种动作(马里奥游戏中的行走、跑步、跳跃等等)
奖励(Reward):代理人从环境中获得的行动反馈(在马里奥的游戏里,即为正确的行动增加的积分/硬币,是一个积极的奖励。因落入陷阱或被怪物吃掉而丢失积分,或损失一条“命”,则是一个消极的奖励)
策略(Policy):根据代理人当前的状态决定一个合适的决策,以最大化地在未来某个时间段内获得正面报酬,最小化获得负面的惩罚
价值函数(Value function):决定什么才是对代理人是有益的
因此,强化学习完全可以被理解为一种游戏方式的学习机制。让机器算法学习做任务,做得好就有奖励做得不好就有惩罚。当然,奖励和惩罚机制本身也是一种算法,这些算法被先天性地植入到机器学习算法的最底层设计中,让其最本能地目标首要考虑就是如何去赢得奖励且规避惩罚。然后,给机器算法一个最终的目标即可!